The tech industry has a rich history of startups that started with a pretty awkward name, and rebranded over time to the big brands we have come to know. Some of those changes are plain fun to remember.
A few days ago, I tweeted this, and it led to a cool thread with plenty of examples and suggestions (Twitter at its best), so I thought I’d compile the results here for easy reference.
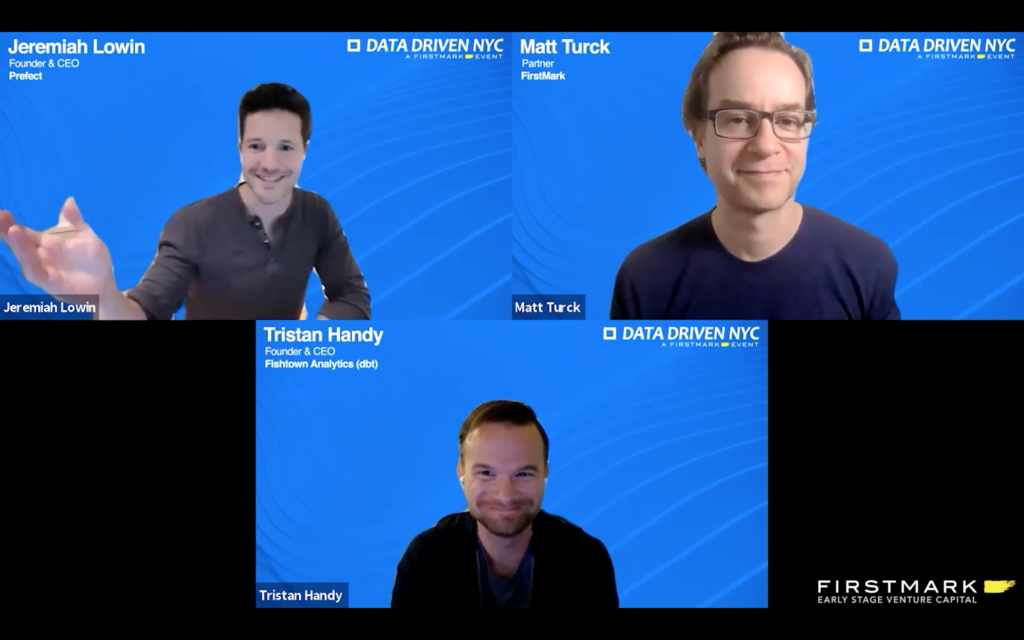
As we close an incredibly active year in the world of data infrastructure, it was a particular treat to host at Data Driven NYC two of the most thoughtful founders in the space, for an in-depth conversation about key trends.
Tristan Handy, is the Founder & CEO of Fishtown Analytics, makers of DBT. DBT is one of the most popular, open-source, command-line tools that enable data analysts and engineers to transform data in their warehouse more effectively. Based in Philadelphia, the company raised both a $12.9M Series A and a $29.5M Series B, back to back in 2020. Tristan also does a great weekly newsletter, The Data Science Roundup.
Jeremiah Lowin, Founder & CEO of Prefect. Prefect is the new standard in dataflow automation, trusted to build, run, and monitor millions of data workflows and pipelines. As another leader in the open-source world, Prefect powers data management for some of the most influential companies in the world.
We had a wide ranging conversation, covering lots of topics: the modern data stack, data lake vs data warehouse, empowering data analysts, workflow automation etc.
Business planning is, of course, one of the vital functions in the enterprise: hard to run a successful company beyond a certain size without a clear sense for objectives and resources.
Yet, to this day, business planning is a often a cumbersome, rigid and time-intensive process. Typically led by the finance team, it is largely done through email, excel spreadsheets and meetings. In large companies involving multiple business units and geographies, the process can take several months. As a result, business planning tends to effectively happen once a year.
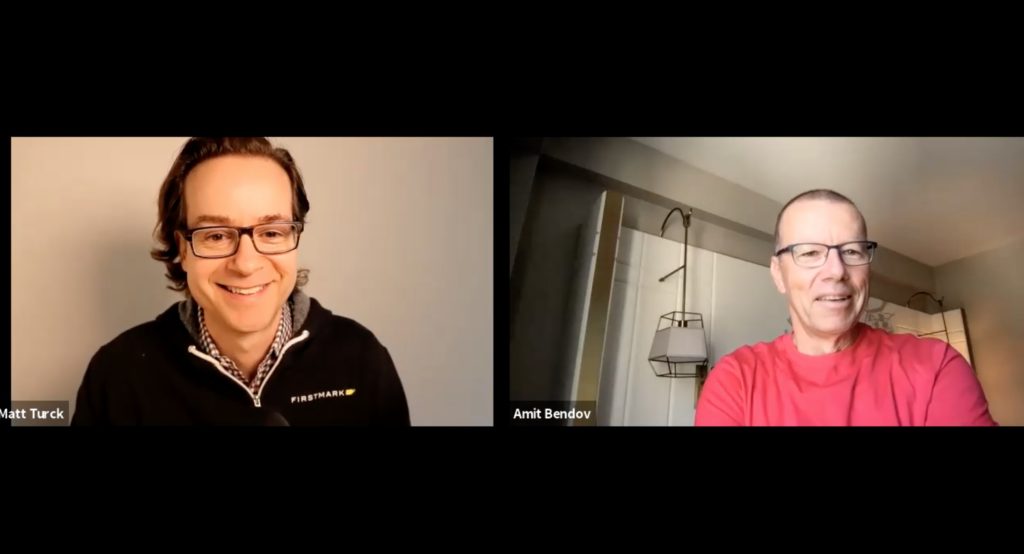
“It wasn’t a walk in the park. Today, Gong is a super hot company. But at that time, we got a lot of no’s, by not stupid people. There were a lot of objections, like salespeople are going to hate it as a big brother, and Google and Amazon will compete with you“, says Amit Bendov, the CEO of Gong.
From those early days of facing skepticism, Gong has indeed become a hot startup loved by customers and ushering its own category, revenue intelligence. It’s also had tremendous fundraising success with VCs, raising $305M in less than 18 months, including a $200M round on a $2.2B valuation, announced in August 2020.
We were thrilled to welcome back Amit at Data Driven NYC, where he had spoken a few years ago, when he was CEO of SiSense.
For anyone following the software industry, there’s been a little bit of snark about C3.ai (“C3”) over the years. Here’s a company that was founded by Silicon Valley royalty (Tom Siebel, who sold Siebel Systems to Oracle in 2006 for just shy of $6B), with seemingly limitless access to capital, that somehow seemed to be pivoting every few years to something new – from energy at first, to the Internet of Things, to Artificial Intelligence.
C3 also largely eschewed the startup echochamber – funded personally by its founder at first, it didn’t raise money from the usual VC suspects, target well-know startups as its first customers, or open source any AI frameworks, working instead with a small group of Fortune 1000 and government customers. As a result, it didn’t build the kind of buzz that often precedes the most notable startups on their way to becoming public.
Lo and behold, what emerges in this IPO is a solid company by enterprise software IPO standards, with $157m in revenue, growing 71% yoy, a 75% gross margin and a $69m loss.
It will be interesting to see how the market reacts to this IPO.
On the one hand, C3 is not growing anywhere as explosively as a Snowflake, and in fact seems to have just had a bad quarter of decelerating growth. There are also other concerns, including account concentration and a substantial loss (not as pronounced as a Snowflake or Palantir, but still on the higher range of the software market).
On the other hand, the tailwinds around the deployment of ML/AI in the enterprise are very strong, and C3 is clearly positioning itself as one of the very first enterprise AI companies to go public: its ticker symbol on the NYSE will be “AI”, and the term “machine learning” is mentioned 56 times in the S-1.
This IPO will be an interesting test for the continued appetite of financial markets for all things AI.
Here’s a quick analysis of the S-1 and main characteristics of the business, put together by my FirstMark colleague John Wu and I.
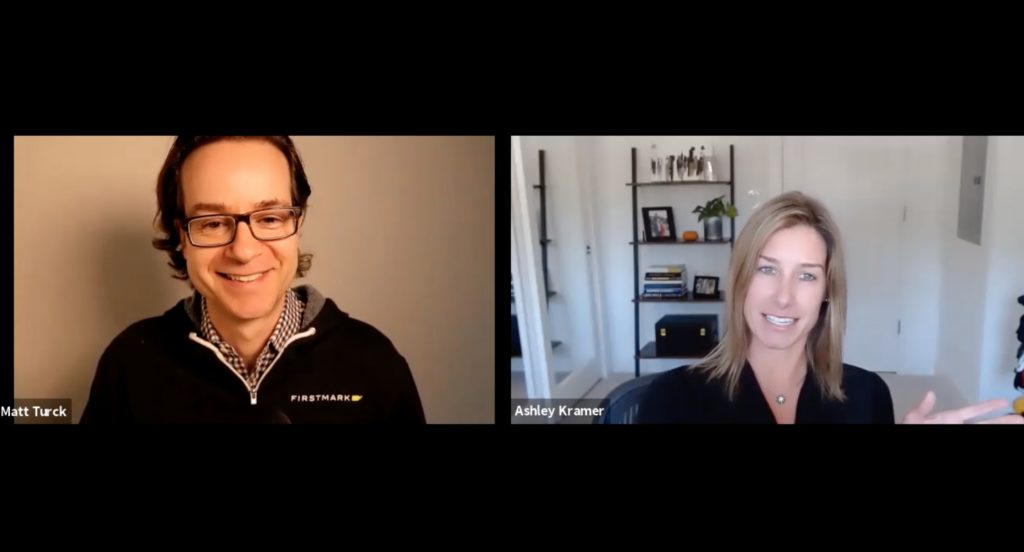
Sisense is a fast-growing business intelligence startup that was ranked #31 in this year’s Forbes Cloud 100, and reached unicorn status at the beginning of 2020 through a $100M Series D led by Insight Partners.
We’ve had Sisense speak twice at Data Driven NYC over the years, first CEO Amit Bendov (now CEO of Gong) (video of the talk here) and then new CEO Amit Orad (video of the talk here).
With all the recent progress, we were particularly excited to hear the update and welcome Ashley Kramer, who recently joined Sisense as Chief Product and Marketing Officer, after a very impressive run at Amazon, Tableau and Alteryx.
We covered a bunch of topics, including:
What does “Business Intelligence” actually mean?
The convergence of BI and data science
How does Sisense position in the context of the consolidation of the BI industry (hint: multi-cloud and focus on different personas, including business users, data analysts and more technical folks)
Where Sisense sits in the modern data stack
How Sisense has been building data network effects with its knowledge graph
Dashboards are great, but embedded analytics are better
As always, Data Driven NYC is a team effort – many thanks to Jack Cohen for co-organizing, Diego Guttierez for the video work and to Karissa Domondon for the transcript!
In a year like no other in recent memory, the data ecosystem is showing not just remarkable resilience but exciting vibrancy.
When COVID hit the world a few months ago, an extended period of gloom seemed all but inevitable. Yet, as per Satya Nadella, “two years of digital transformation [occurred] in two months”. Cloud and data technologies (data infrastructure, machine learning / artificial intelligence, data driven applications) are at the heart of digital transformation. As a result, many companies in the data ecosystem have not just survived, but in fact thrived, in an otherwise overall challenging political and economic context.
Perhaps most emblematic of this is the blockbuster IPO of Snowflake, a data warehouse provider, which took place a couple of weeks ago and catapulted Snowflake to a $69B market cap company, at the time of writing – the biggest software IPO ever (see our S-1 teardown). And Palantir, an often controversial data analytics platform focused on the financial and government sector, became a public company via direct listing, reaching a market cap of $22B, at the time of writing (see our S-1 teardown).
David Cancel puts the “serial” in serial entrepreneur. David has founded a total of five software companies over the years, which he says make him “certifiable”. The list includes Performable, which was acquired by Hubspot, where David subsequently spent three years as Chief Product Officer.
In 2015, David left Hubspot to start Drift, a Boston-based conversational AI platform for marketing and sales. The company has grown very rapidly and now has a whopping 50,000 customers. Drift has raised a total of $107M from a number of venture firms including Sequoia, General Catalyst and CRV. The company has also been recognized as a Forbes Cloud 100 company.
David also has built a very strong presence and brand in the entrepreneurial community. He writes a popular newsletter, ‘The One Thing’ and hosts a long-running podcast, ‘Seeking Wisdom’. He’s very involved in a number of startups as advisor and angel investor. He’s also an Entrepreneur-in-Residence at Harvard Business School.
David and I had a really interesting, wide-encompassing conversation at our most recent Data Driven NYC event, where we covered a range of topics including:
Building a global SaaS brand with 50,000 customers in an astonishingly short amount of time
How Drift was founded to take advantage of a fundamental paradigm shift
Creating a new type of CRM, driven by conversational data, with automation at the core
One of the biggest recent trends in the data world recently has been the rapid emergence of the “modern data stack”.
This stack is largely centered around the cloud data warehouse, with its massive scalability and elasticity capabilities. Snowflake’s blockbuster IPO this week, and the underlying performance of the company, demonstrate the level of excitement from both customers and investors about the data warehouse.
But the modern data stack is more than just the data warehouse, there’s a whole pipeline involving other technologies, where data gets collected, stored and analyzed. Downstream from the data warehouse, you find business intelligence solutions, as well as some machine learning platforms, to analyze the data. Upstream from it, you find solutions that focus on extracting data from various sources and loading it into the data warehouse (ETL/ELT).
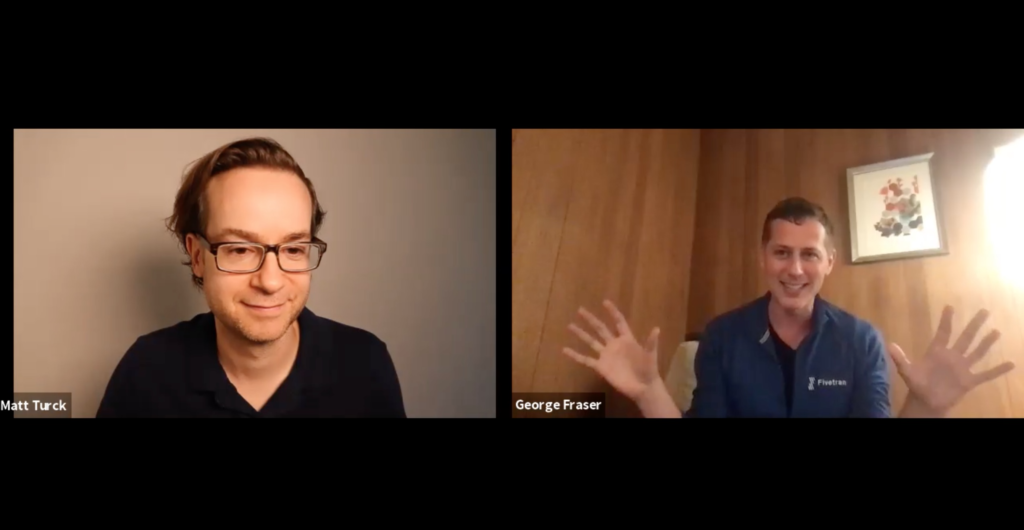
This is where Fivetran comes in. A fast-growing company with a unicorn status, it automates data integration from source to destination, through a large library of connectors.
It was very fun to host Fivetran’s CEO, George Fraser, at our most recent Data Driven NYC event. We had a great conversation, both very approachable for a non-technical audience but also interesting for more technical folks.
Every startup is not just a business adventure, but also a human journey. Today, Sense360 is getting acquired by Medallia (NYSE: MDLA), see the press release. It’s one of those bittersweet moments where I’m very proud of the team and company, but also realize I’ll really miss working with this great group of folks.
My journey with Sense360 started before there was a team, a product or even a company.
The Palantir S-1 is a long and meaty read, and a pretty fascinating one considering the company was highly secretive, and often controversial, for so many years. It is also written in a very opinionated style: the newly Colorado-based company takes aim at Silicon Valley and is not exactly charitable to its competitors.
Particularly compared to a Snowflake that has had a meteoric rise since inception in 2012 (see our Snowflake teardown here), the Palantir S-1 also presents the picture of a company that, while unique, has had a long road since it was founded in 2003.
It seems that the company went through an important transition in the last couple of years on the product and go to market front – evolving away from a services company into more of a software one – perhaps in anticipation of an IPO.
Ironically, in some ways, this evolution has made Palantir look more like the Silicon Valley companies it feels so different from.
Here are some quick thoughts and notes (from Avery Klemmer and myself)
The Snowflake IPO is shaping up to be particularly exciting. Their S-1 shows very impressive metrics across the board, including explosive revenue growth at scale (growing 174% annually to $264.7 million for the fiscal year ended January 31, 2020), and “land and expand” motion (169% net revenue retention in 2020), making Snowflake one of the fastest growing enterprise companies ever.
In addition to the intrinsic merits of the company, this is yet another example showing how gigantic the market is for data technologies (storage, analytics, machine learning, etc.). Snowflake estimates its addressable market at $81B.
We’ve had the pleasure of hosting Snowflake’s former CEO, Bob Muglia, a couple of times at our Data Driven NYC event of the years (see videos below), and it’s been really fun to watch the company grow.
Celonis was founded in 2011 by three students who didn’t know they wanted to start a company, but fell in the love with a school project.
Today, Celonis is a Forbes Cloud 100 company, and the leader in a very interesting category, enterprise performance acceleration software, leveraging a company’s data exhaust to understand which processes work and which need to be be optimized, through process mining technology.
It’s also a unicorn startup with $367 million raised to date, most recently at a $2.5 billion valuation from investors such as Accel, 83North, our friends at Arena Holdings (who kindly introduced us to Alex) and Qualtrics founder Ryan Smith, who spoke at Data Driven NYC a few years ago, and then famously went on to sell his company, Qualtrics, to SAP for $8 billion.
We had a really fun chat at our most recent Data Driven NYC, with Celonis co-CEO Alexander Rinke:
How Celonis started as university consulting project when the founders were 21
How Alex waited several hours outside the VIP area of a tech event, until he was able to talk to the founder of SAP, which resulted in a transformative partnership
How the company was bootstrapped for 5 years before taking any VC money
What it takes for a startup to successfully expand internationally
What is process mining software and how does it work
Go to market strategies – horizontal vs vertical
And a lot more
Here’s the video, and below is a full transcript of the chat:
While we miss the special energy of having 350+ people in a room every month, it’s been fun to settle into the routine of hosting the online version of Data Driven NYC — our 19,000 person community focused on all things data, AI/ML and enterprise software. Our events are free and open to all, and having them online has enabled many more folks around the world to attend them live – to the point that my co-organizer Jack Cohen and I have been mulling renaming the event “Data Driven Global”.
At the most recent event a few days ago, we had the pleasure of hosting Nate Stewart, Chief Product Officer, and newly appointed Board Member, at Cockroach Labs.
Cockroach is an exciting, fast-growing startup. Named to the 2020 “Future Unicorn” list by CB Insights and Fast Company, it is the company behind CockroachDB, a distributed database with standard SQL for cloud applications. The company has raised $195m to date, from a long list of great investors such as Benchmark, GV, Index, Redpoint, Altimeter, Tiger, Bond, Work Bench – and our firm FirstMark, since the very first round of funding.
This generated a good discussion in the thread with some great input.
VPs of Finance are a little bit of a counter-intuitive hire in early-stage startups. It’s pretty obvious to most founders why they need senior people in charge of engineering, product, sales and marketing. You need people to build, and you need people to sell.
But finance feels like a back-office role, a cost center. Sure, we’ll need one, but “later”. If we hired them now, what would they do all day? Would they have enough work? Can’t we just outsource the role for now? Shouldn’t we prioritize other roles, like Head of People or Head of Legal? Can we even afford one? Shouldn’t we hire one or two more engineers instead?
Yet, interestingly, I’ve never heard a startup CEO say after the fact that they regretted hiring a VP of Finance too early. But I’ve heard several CEOs say they wish they had hired one much earlier.