In the furiously competitive world of tech startups, where good entrepreneurs tend to think of comparable ideas around the same time and “hot spaces” get crowded quickly with well-funded hopefuls, competitive moats matter more than ever. Ideally, as your startup scales, you want to not only be able to defend yourself against competitors, but actually find it increasingly easier to break away from them, making your business more and more unassailable and leading to a “winner take all” dynamic. This sounds simple enough, but in reality many growing startups, including some well-known ones, experience exactly the reverse (higher customer acquisition costs resulting from increased competition, core technology that gets replicated and improved upon by competitors that started later and learned from your early mistakes, etc.).
While there are various types of competitive moats, such as a powerful brand (Apple) or economies of scale (Oracle), network effects are particularly effective at creating this winner takes all dynamic, and have been associated with some of the biggest success stories in the history of the Internet industry.
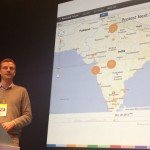
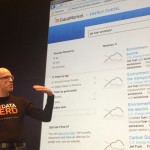
Network effects come in different flavors, and today I want to talk about a specific type that has been very much at the core of my personal investment thesis as a VC, resulting from my profound interest in the world of data and machine learning: data network effects.