
Artificial intelligence is, of course, all the rage in tech circles, and the press is awash in tales of AI entrepreneurs striking it rich after being acquired by one of the giants, often early in the life of their startups.
As always, the reality of building a startup is different, especially when one aims to build a self-standing company for the long term. The path to success in AI requires not just technical prowess but also careful thinking and execution through a range of strategic and tactical questions that are specific to this domain and market.
One possible framework to think through these topics is this “5P”list: Positioning (finding blue ocean), Product, Petabytes (data), Process (social engineering) and People.
This week at the excellent O’Reilly Artificial Intelligence Conference, I covered those topics (as much as a 40 minute presentation allows), with the help of Peter Brodsky, CEO of HyperScience.
Here is the presentation (SlideShare version at the end):
I’m approaching this discussion from a VC perspective (and also through the dozens of conversations I’ve had with founders of AI and Big Data startups at Data Driven NYC, the monthly event I organize).

Peter Brodsky is building a great enterprise AI startup, and he’ll keep me honest by adding the entrepreneur’s perspective!






This “5P” framework is just one way of thinking through those issues — Positioning means “market positioning”, while “Petabytes” means “large amounts of data”



Just about every major tech company is working very actively on AI. For young startups, those companies represent a very different type of incumbents than what startups in the 90’s and 00’s faced — tech native and aggressive companies that themselves were startups not that long ago, for many of them.

Larry Page was thinking about Google as an AI from the very beginning.

Fast forward to today, it is more of a priority than ever.

Many of the fathers of deep learning were working in semi-obscurity for several decades. They have now become the new rockstars of AI.
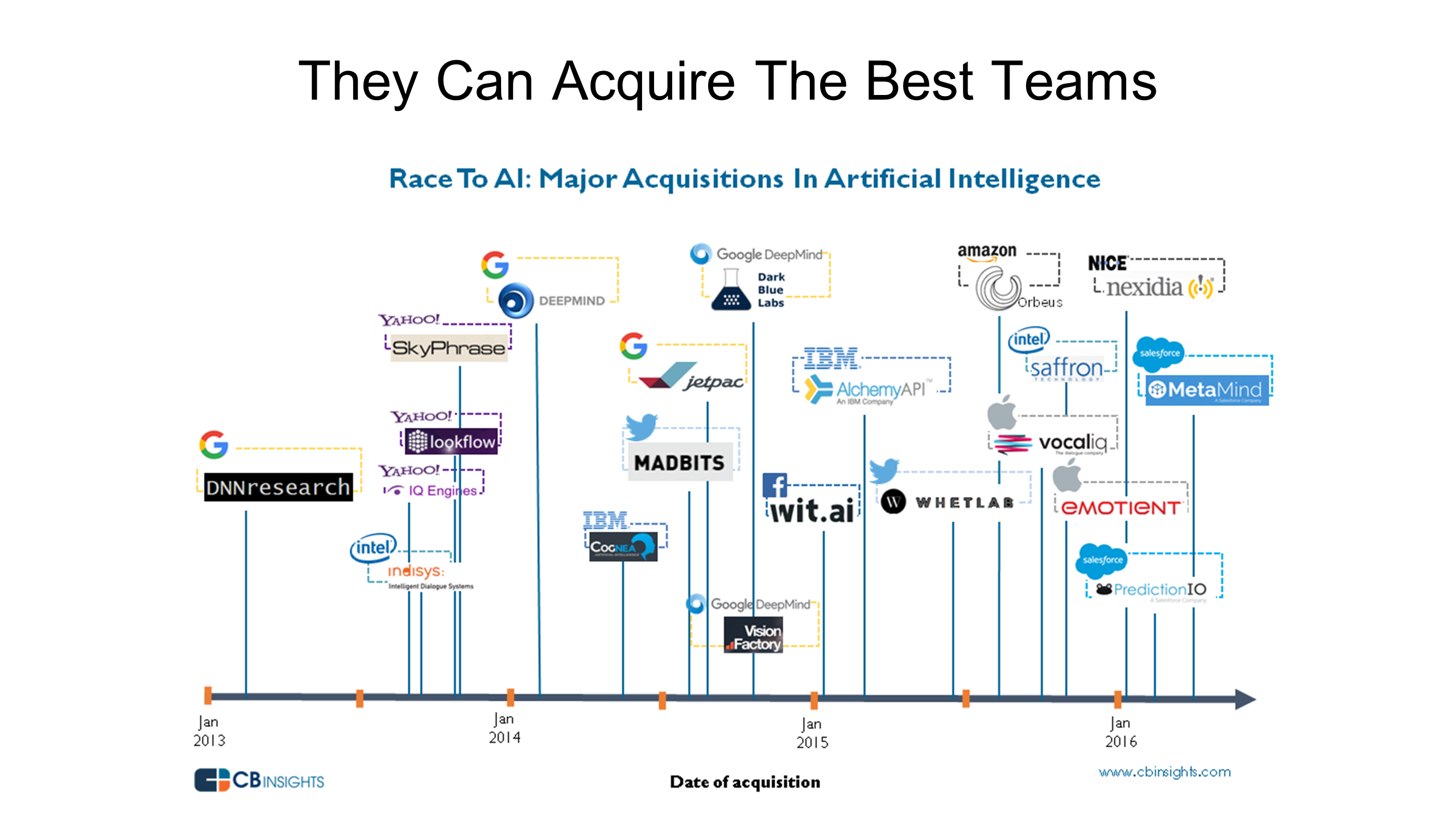
Not only can the large tech companies hire the best talent, they’re willing to snap up AI startups quickly when needed.

Much has been written about how having huge amounts of data makes a big difference in AI. There are nuances to this and interesting developments around leveraging smaller amounts of data, but it nonetheless an undeniable advantage.

When there are multiple 800 pound gorillas in your industry, you need to position away from them.

Everything else being equal, it is safer for a young AI startup to focus on a vertical problem.










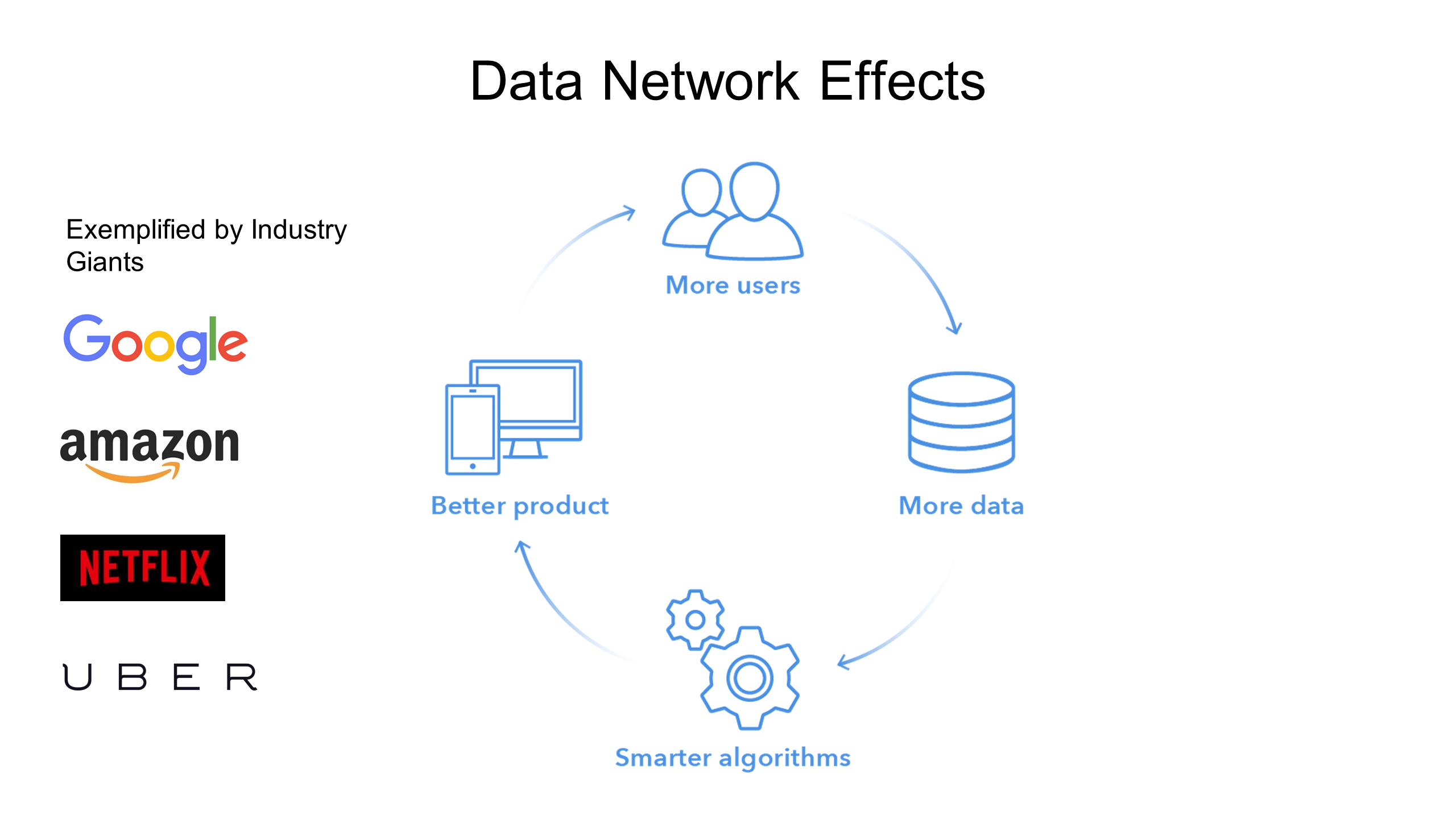
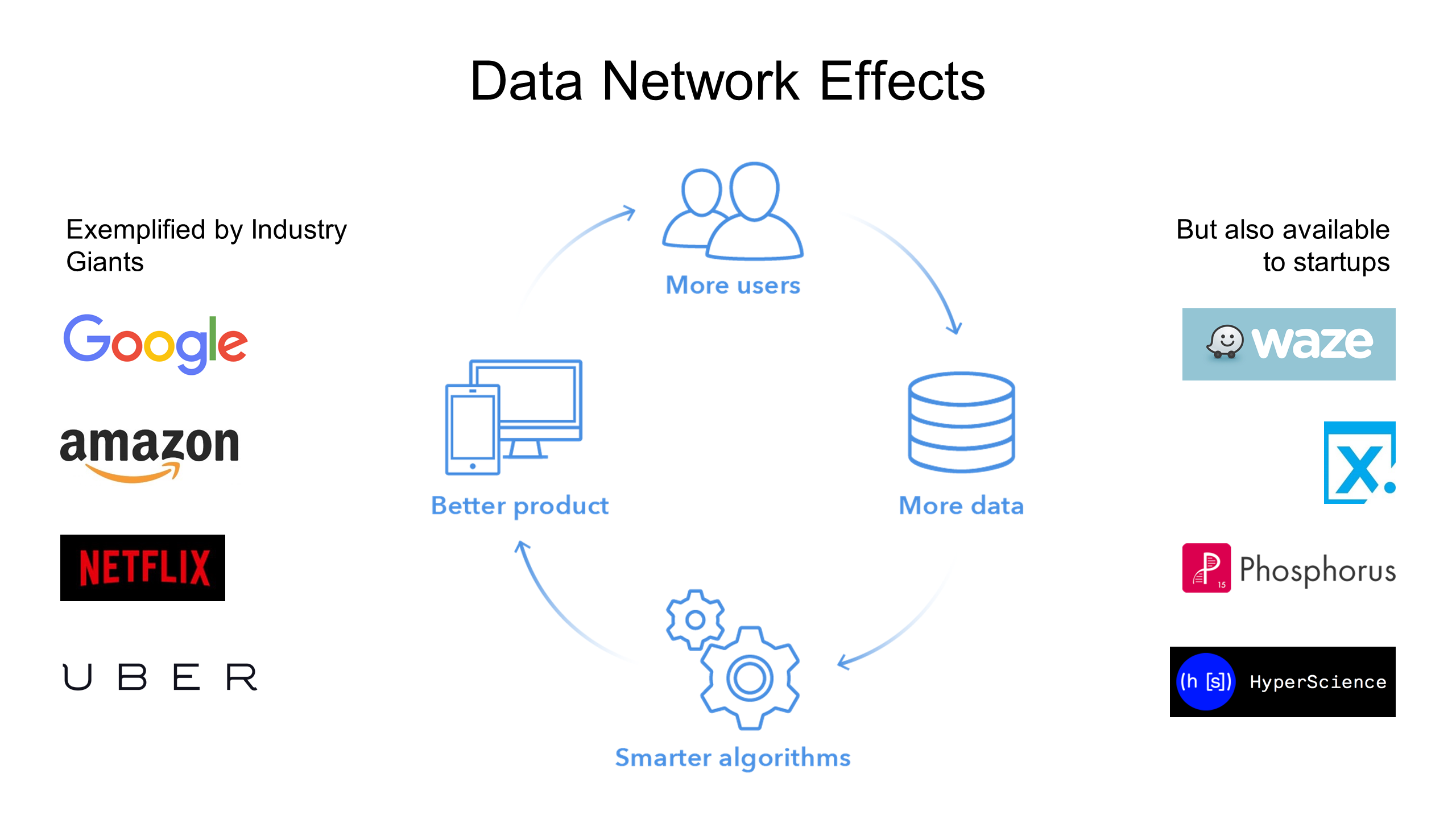
For more thoughts on data network effects, see my post on the topic here.

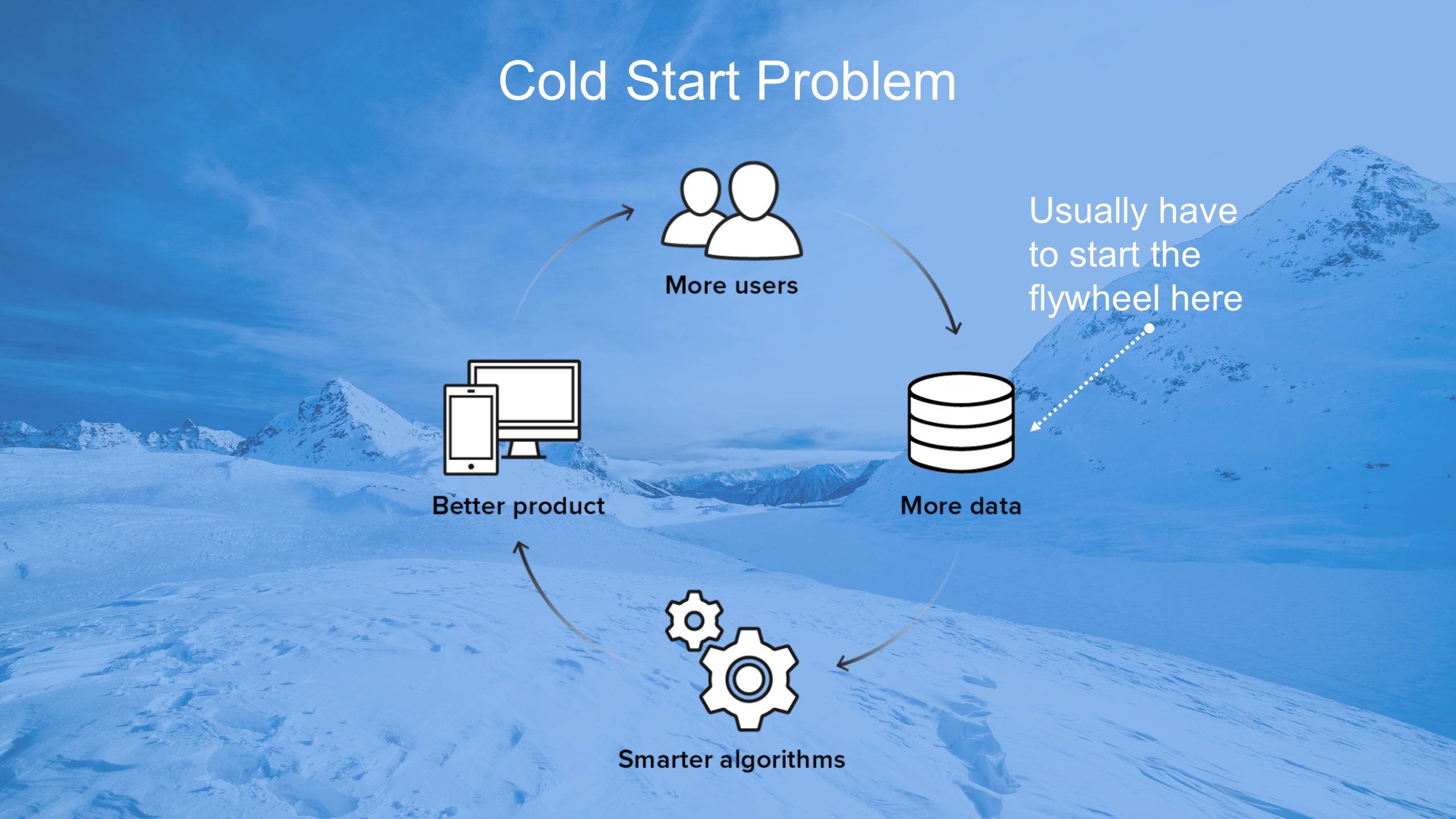

One approach is to obtain existing data sets, either public or commercially available.

Another approach is to create focused crawlers that go out on the web and fetch data that is relevant to the specific problem you’re trying to solve.

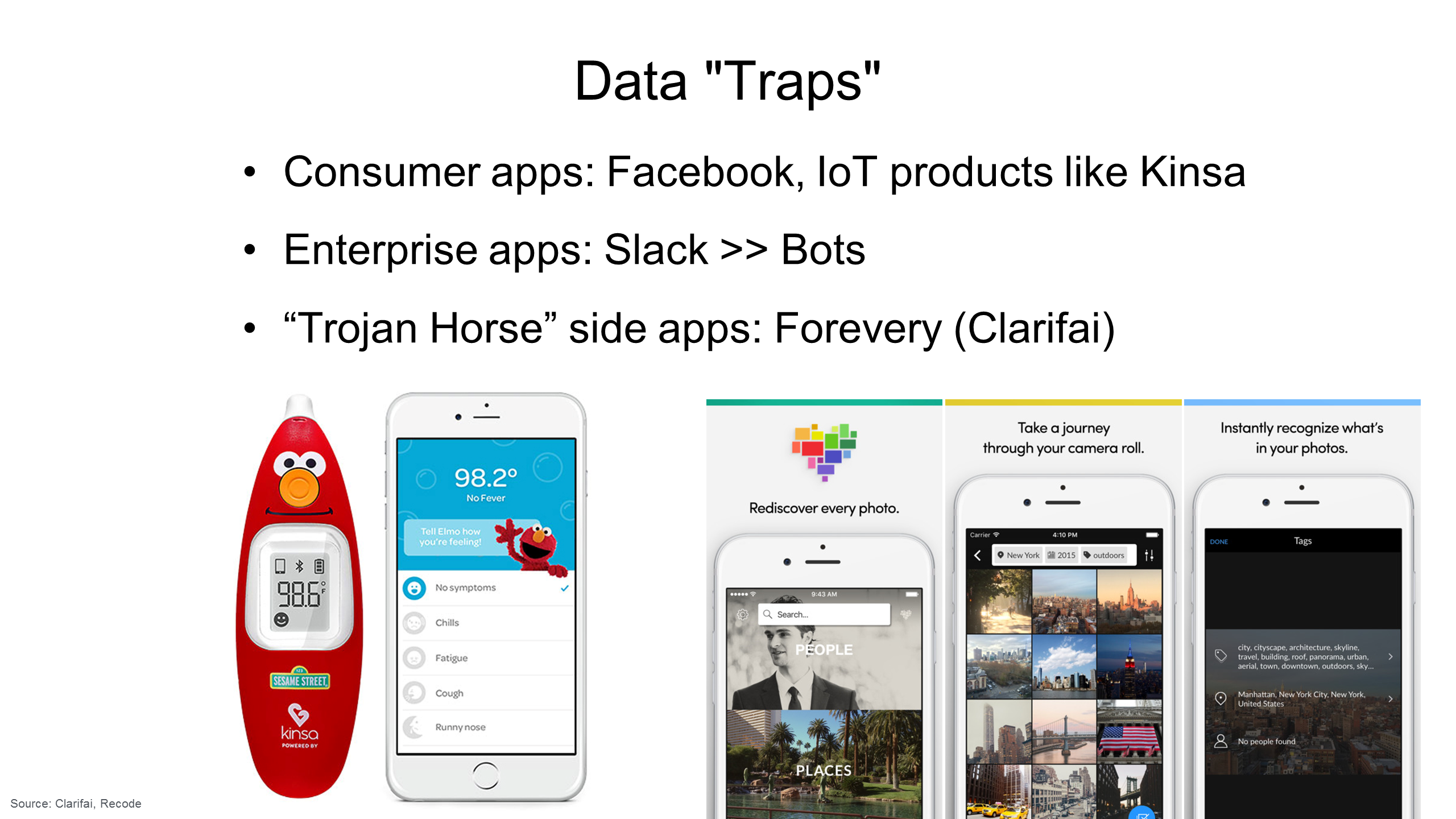
A data “trap” collects large amounts of data by providing a lot of value to users from Day 1. The data exhaust is just a by-product of the utility of the product.

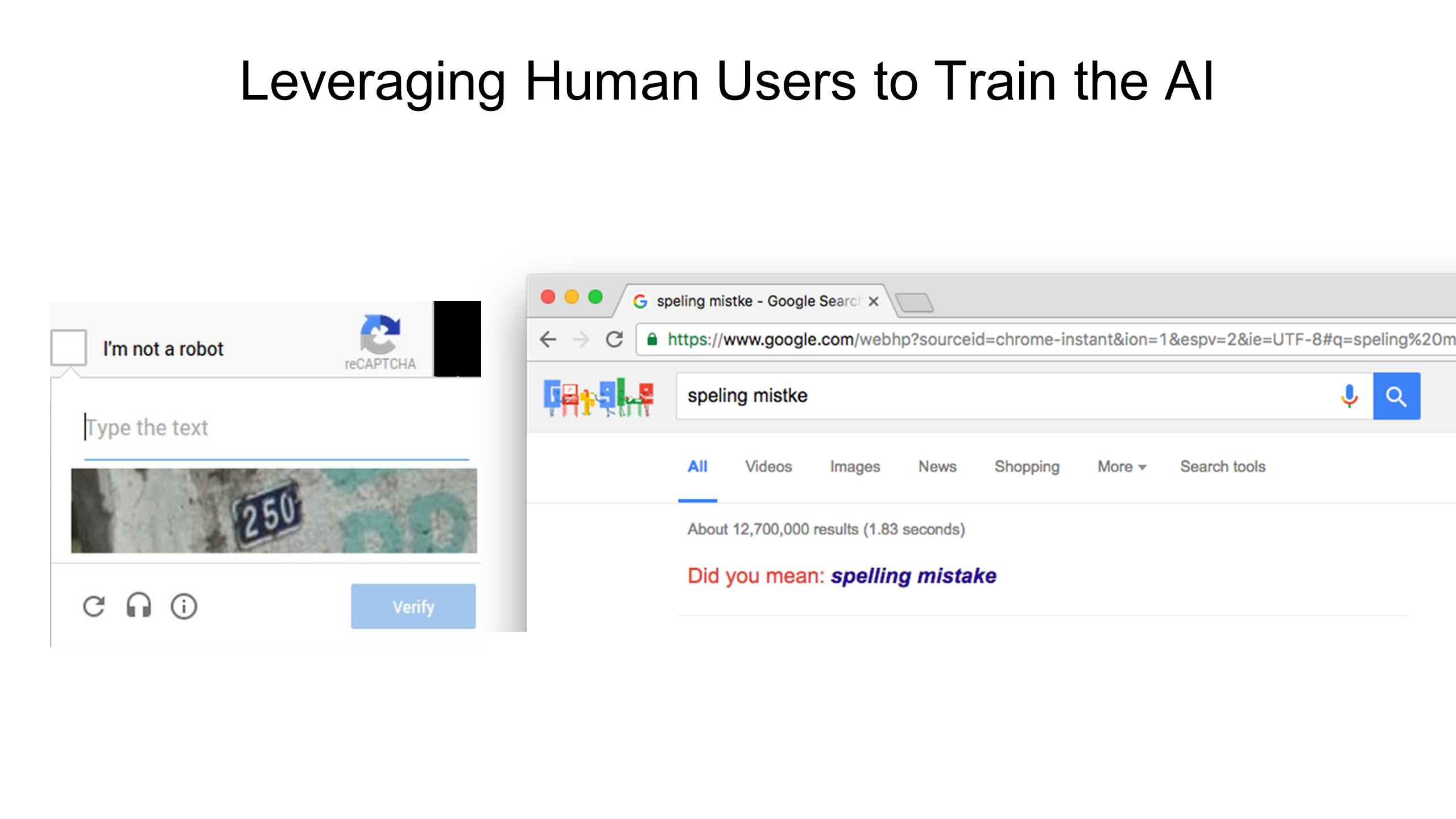
Getting things started with humans (data aggregation and labeling) is a smart strategy to address the cold start problem. Over time the mix between human and machine evolves, the end goal being full automation.









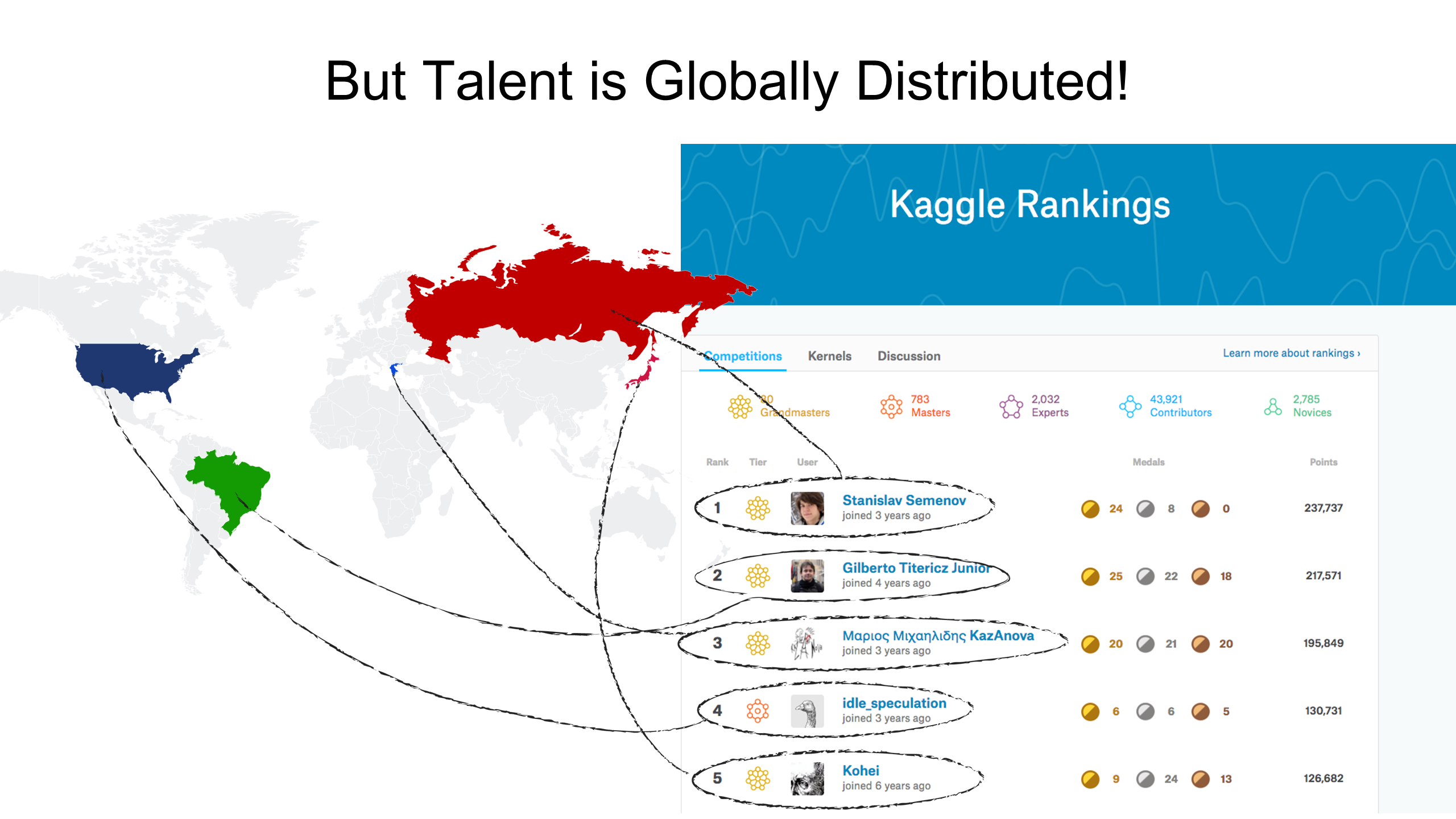





As for any startup, there are perils along the way for anyone building an AI company. At the same time, with thoughtfulness about positioning and overall strategy, it is a very unique and exciting time to be building a startup in the space.

Well said, Lin.
And here’s the SlideShare version:
Thanks for posting. You mentioned Facebook in data traps. Can you elaborate?
You also need some good technology like http://ai.neocities.org and an AI Theory like http://mind.sourceforge.net/theory5.html upon which to build a genuine AI not with Deep Learning but with Deep Thinking.